

Working with old code? Here’s everything you need to know about managing and improving legacy systems.
What is software? First and foremost, it’s code, but we can also think of it as a living, ever-evolving thing, because it’s written by people. In the same way that every one of us has our past experiences and memories, software is built over many years, and what might have been there before – its “past selves” – become known as legacy code.
Legacy code is in almost every software project. And in its worst state, it can stifle innovation, prolong a development lifecycle, and affect engineering morale.
In this article, we will dive into what goes into building software and how legacy code plays a role on every level: the code, the individual, and the team. We will look at the psychology behind what makes software so challenging to work on, and how to improve it for everyone involved, developers and customers alike.
The core elements of building software
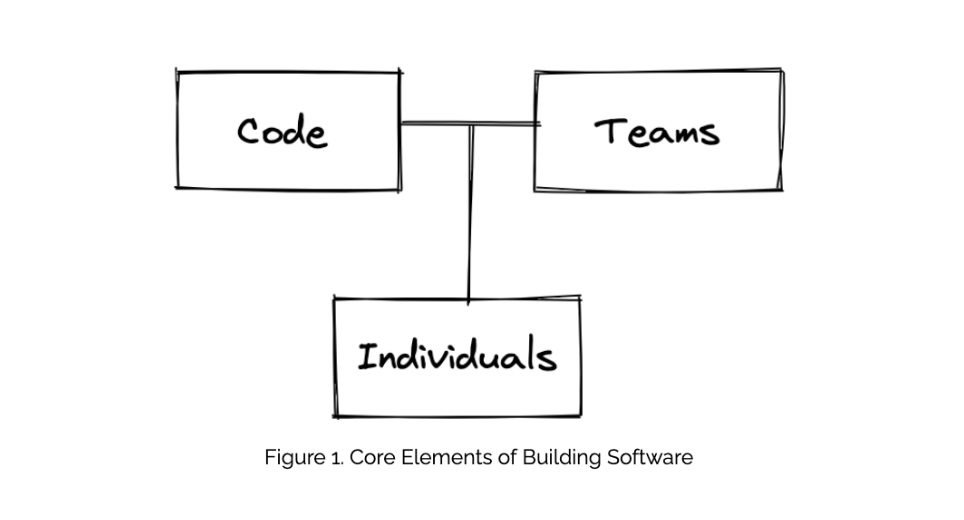
There are three building blocks when it comes to software development: individuals, teams, and code.
When we think about software, we usually envision a computer program an individual has made. Even in programs that rely on artificial intelligence, a person has written the code for these applications to “write themselves.” Lastly, we have to think about scale. Most high-impact applications are created by a group rather than single individuals. People are particularly successful when they come together as a team.
As with any system that has more than one moving piece, each element adds complexity in how it interacts with other parts.
The psychology behind broken software
Nothing is forever in life, including software. It’s not “if” but “when” the system will break. It could be regressions, bugs, performance issues, or many other things. While it’s easy to disregard or deprioritize small breaks, this approach can lead to even more significant failures. The reason why it can be detrimental to overlook minor issues goes back to the human element of building software and its psychology.
One of the most interesting parallels between making software and sociology is the broken windows theory. This theory states that visible signs of disorder create an environment that encourages even more chaos. For example, if a window is smashed in a neighborhood building and is left without fixing, then reasonably soon, other windows will be broken, walls defaced, and the entire area might become unsafe.
We can apply the same theory to how we treat our software. If we let these small breaks, these “window cracks,” into an application, the app will soon be completely broken. Since we discuss software as a combination of three core elements, we can apply this theory to each of them and see where “broken windows” can start appearing.
This article will only talk about a coding element of software building, but it doesn’t mean that individuals and teams are any less critical to our application’s success. It’s actually the opposite: people are the most complex component of any system. But here we’ll start with the most basic part of what goes into making software: our code.
The risks of making changes to software
Before we dive further into the code behind our software, we need to step back and ask ourselves whether we should even care about software and its code in the first place. The answer is simple: we shouldn't care about the software. Instead, we should care about getting our users exactly what they need.
Our customers don’t want specific features, they want the behaviors behind them. For example, a user doesn't need yet another button on their web app; what they really want is to be able to export a report with their weekly analytics.
“Behavior over features” is the main principle to uphold when developing software. This motto is why the infamous phrase, "it's not a bug, it's a feature”, is a valid approach. Our customers get used to a particular email format or a navigation menu position, so even if we discover that the way a feature works is not optimal or relies on an underlying bug, we have to be extremely careful when making changes to the code.
Whenever we are making changes to the existing code, we’re doing what we call “refactoring.” We might want to refactor the code because we are working on a new feature, for example adding account information to the navigation bar. It might be a bug fix that requires changing the code, which could cause unexpected behavior. Sometimes refactoring can be a part of a significant rewrite of an application, for example if we want to change its architecture.
The list of possible reasons for refactoring is very long and project-specific. What's important is that we understand that changing the existing code can unexpectedly alter the behavior that our customers are used to and that it is usually something we want to avoid. We could also cause breakages to seemingly unrelated areas of our app. For example, adding a few pixels to the profile image can push some other fields of the screen entirely.
These unexpected breakages are called “regressions.” We use tests to ensure the current behavior of our code is preserved and is “correct.”
All of these nuances and potential dangers of working with existing code are where legacy code comes into play. Now we've established the importance and risks of working with software, let's dive into this fundamental aspect of working with legacy systems.
Understanding legacy code and how to deal with it
Legacy code is a reasonably broad term, and some people go as far as to call any software legacy code as soon as it’s written. However, we will go with something more concrete and rely on a definition by Michael Feathers, author of a fantastic book called, Working Effectively with Legacy Code. He defines legacy code as any code without tests.
With this definition in mind, let’s say we wanted to change our legacy code. Right away, we are faced with a catch-22. Usually, production code has to be written in a certain way to make it testable. Since legacy code is inherently code without tests, we often need to refactor it. But as we established before, refactoring code without tests could change our software's existing behavior, causing regressions.
Since we established that adding tests and refactoring legacy code carries certain risks for our software, we should continually evaluate whether it’s worth changing this code. Sometimes, leaving the legacy code alone and unchanged is the correct decision.
We should always consider what the cost of making the change is. We need to calculate the Return on Investment (ROI) of refactoring our code and adding more tests. Changing legacy code simply for the sake of doing it is meaningless for our customers, and as we remember, it's the end users we ultimately care about. This is why we should use factual data when proposing changes to legacy code. Should we do it if it takes one engineer two weeks to rewrite a particular legacy code that will result in 10x load time improvement? If the answer is yes for your organization, then it’s an easy decision to make towards refactoring legacy code and adding more tests.
The critical takeaway is that legacy code is not something inherently wrong, but we need to spend time understanding. Sometimes, legacy code works as our users expect, and if the cost of changing it outweighs the long-term benefits for our users, it might be justified to keep the code unchanged.













.png)






.png)



 (1).png)



